
Back in Rhodes, piña colada in hand and my feet dipped in the pool, I wrote about building yet another algo-trading framework. That post chronicled the shift from overengineered C++ and Go experiments to a more pragmatic, productive Python setup, powered by GitHub Copilot and AI pair-programming. It was lightweight, testable, and already backtesting a simple RSI trailing stop strategy via Alpaca’s market data API.
Since then, that experimental repo has evolved into something far more structured: a FastMCP 2.0-compatible server hosting two composable tools: get_historical_data and run_backtest. These tools, abstracted from my core logic, form the backbone of a modular and agent-friendly trading system. They allow for decoupled execution paths, better observability, and—most importantly—plug-and-play access from LLMs.
Why Tools, Not Agents (At First)
Originally, I thought I needed to go full agent: I fired up LangGraph, sketched out a multi-node decision chain, and started wiring everything together. Along the way, I discovered LangSmith—a powerful tracing and observability platform for LLM agents—and that’s when I truly began to realise the potential of agentic tracing—not just for debugging, but for understanding decision paths and tool usage patterns in a way that felt almost forensic. It made debugging logic flows far easier, and I briefly flirted with the idea of fully orchestrating execution through LangGraph.
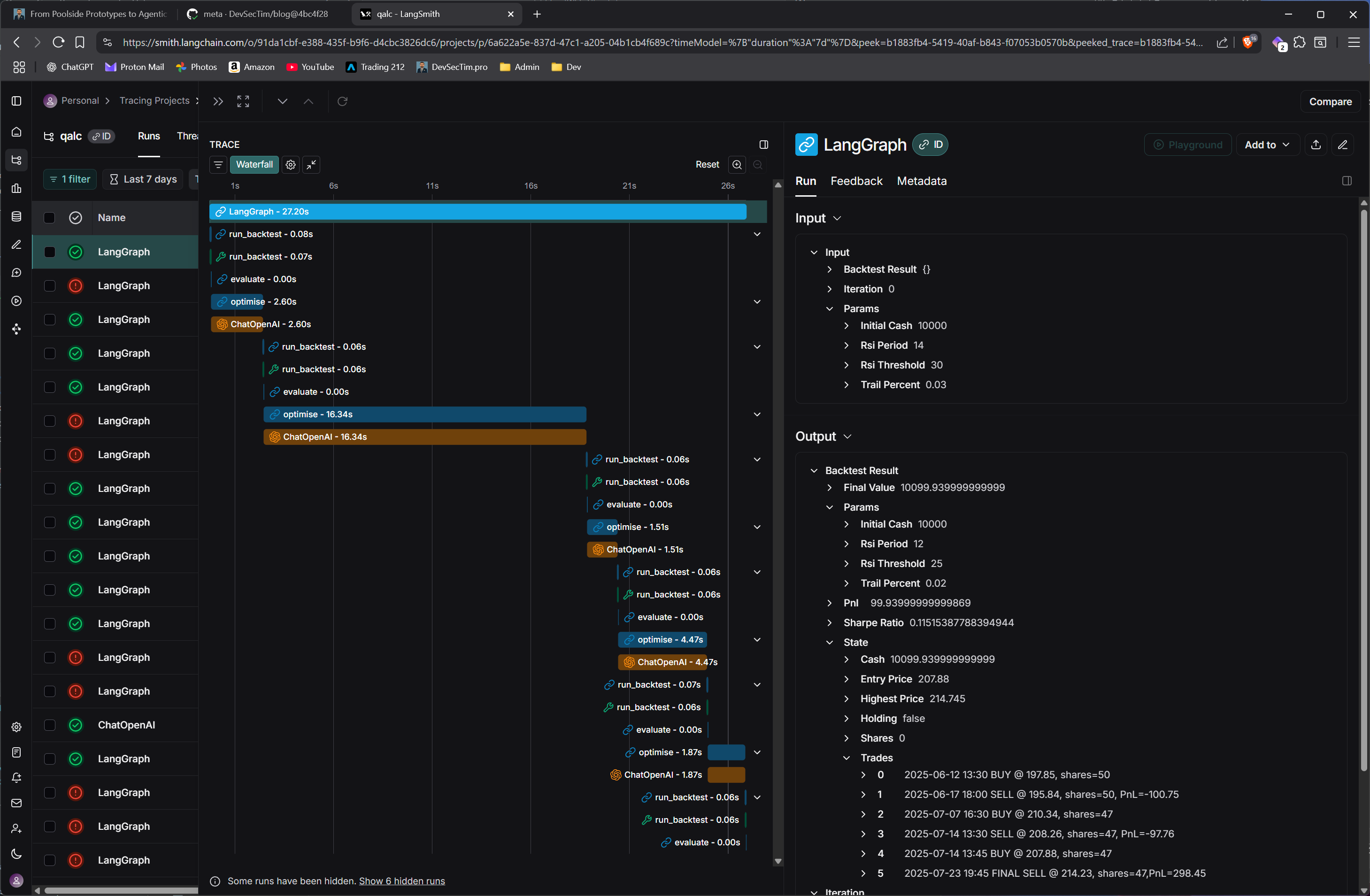
But something didn’t sit right. I wasn’t building an LLM-powered user assistant; I was building tools. This wasn’t about creating a chatty co-pilot—it was about empowering a language model to compose functional queries and evaluations on demand.
The epiphany came when I saw how FastMCP lets you expose callable tools directly to LLMs. With that model, the agent isn’t a monolithic control flow graph—it’s the LLM itself, making dynamic choices from a menu of tools based on user intent. That flipped the architecture on its head. Suddenly, it wasn’t about writing agents; it was about empowering them. You don’t have to write the brain—you just give it hands and let it figure things out.
From Functions to Tools
Both get_historical_data and run_backtest began as ordinary Python functions. The former retrieves OHLCV data using Alpaca’s API, while the latter takes that data (as a pandas DataFrame) and runs a strategy—currently the RSI trailing stop or a basic buy-and-hold—returning JSON-serializable results for further analysis or chaining.
To MCP-ify them, I wrapped each function into a BaseTool class (using LangChain’s tooling), added parameter schemas, and ensured input/output formats were LLM-friendly. The design prioritises clarity and robustness—the LLM doesn’t need perfect formatting, but it does need clear interfaces and predictable behaviour.
Now, an LLM can:
- Ask for historical data with specific symbols, granular timeframes, and test spans.
- Feed that data into one or more strategies via backtest calls.
- Retrieve backtest results, which can later be parsed, visualized, or evaluated by the LLM itself.
All of this is running via the qalc MCP server, exposed over streamable-http. Seeing the FastMCP 2.0 ASCII banner light up in my terminal felt oddly satisfying—a small but meaningful signal that the system was real, modular, and ready for composable LLM workflows.
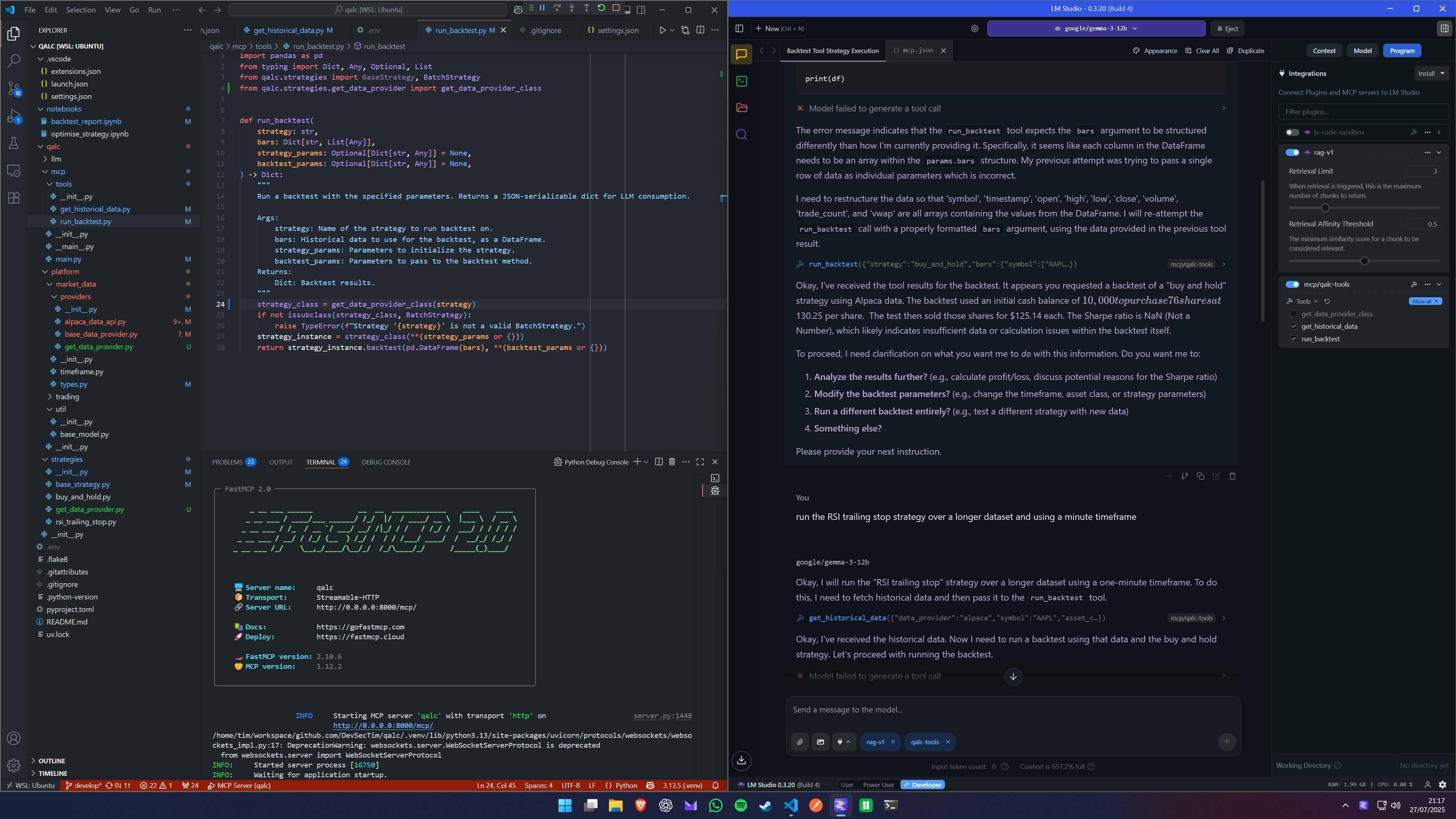
Testing with LM Studio (and My GPU Screaming)
To test the system, I loaded the local server into LM Studio, connected to my custom tools, and ran a local LLM (Gemma 13B) right on my GPU. When the LLM started typing, my GPU’s coil whine surged—it literally squealed in time with the response tokens. It was like hearing your machine think. Debugging suddenly became auditory.
The ability to test toolchains in LM Studio has been a game-changer: no cloud latency, immediate feedback, and full control over the tool context. I could debug prompt formatting, data type mismatches, schema alignment issues, and tool routing all in one place. It made the abstract concrete—I wasn’t just writing code; I was conversing with it.
I iterated rapidly, refining the tool outputs to be more LLM-consumable, clarifying parameter definitions, and experimenting with prompting strategies to guide the model. I even began crafting “prompt contracts” to serve as affordances for guiding LLM behaviour—hints on how and when to use each tool.
What’s Next?
This is just the beginning. Future plans include:
- Expanding the strategy library beyond RSI and buy-and-hold, including MACD crossovers, Bollinger Band systems, and multi-factor filters
- Improving the LLM interface with better descriptions, argument examples, and dynamically generated prompt hints
- Integrating hyperparameter optimisation tools (LLM-driven or evolutionary)
- Experimenting with multi-step plans: “Get historical data, run 3 strategies, compare Sharpe ratios”
- Allowing chained reasoning where an LLM can iterate on results: “That Sharpe ratio was low, try tweaking the RSI parameters”
- Plugging in with A2A for distributed agent coordination, allowing cross-agent communication and specialisation
The core idea remains: let the LLM think, let the tools do. The LLM doesn’t need to be the strategist or the executor; it just needs to know what tools are available and how to use them.
Until then, I’ll be refining prompts, writing more tools, and listening to my GPU sing in harmony with the hum of possibility.
Want to try the framework or contribute? Check out github.com/DevSecTim/qalc – or just open LM Studio, load your favourite model, and talk to your tools.